
-
- Downloads
add fig/poster-2023-02-14/initial-results
Showing
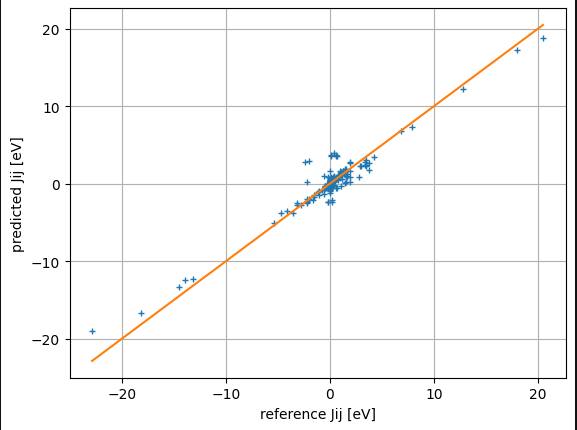
- fig/poster-2023-02-14/initial-results/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.2.png 3 additions, 0 deletions...results/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.2.png
- fig/poster-2023-02-14/initial-results/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.2.txt 32 additions, 0 deletions...results/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.2.txt
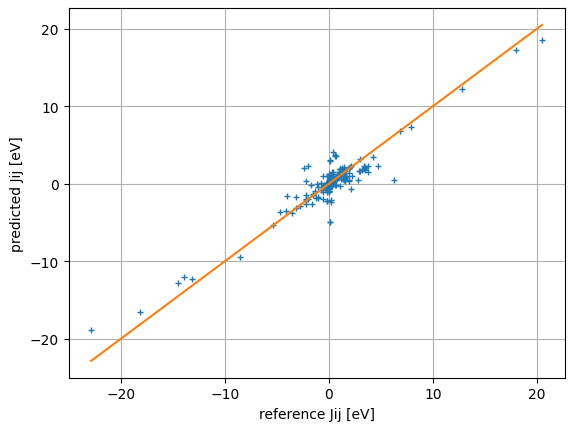
- fig/poster-2023-02-14/initial-results/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.25.png 3 additions, 0 deletions...esults/jij-poyen-soap-n-8-l-8-r-4-s-1.0-tt-split-0.25.png
130 B
{kind=link}
{kind=link}